
一、题目描述。

我们需要训练得到一个逻辑回归分类器来对图片进行二分类(是猫和不是猫),通过正向传播和反向传播来对参数进行优化。官方网站给出的题目形式是填空编程,这里我将给出完整的代码,可能和官网上的有些出入,但是大致相同。
二、相关库
1.numpy:强大的科学计算库,主要用于矩阵的计算
2.matplotlib:绘图库,可以绘制损失曲线
3.h5py:是与H5文件中存储的数据集进行交互的常用软件包三、编程步骤
1.数据预处理
lr_utils.py 用于图片数据的读取:
import numpy as np
import h5py
def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes每张图片的大小为64*64像素,而每个像素点由RGB三原色组成,所以每张图片的数据维度为(64,64,3),所以一张图片需要12288个数据确定。load_dataset 返回值的含义:
train_set_x_orig:训练集图像数据,一共209张,数据维度为(209,64,64,3)
train_set_y_orig:训练集的标签集,维度为(1,209)
test_set_x_orig:测试集图像数据,一共50张,维度为(50,64,64,3)
test_set_y_orig:测试集的标签集,维度为(1,50)
classes : 保存的是以bytes类型保存的两个字符串数据,数据为:[b’non-cat’ b’cat’]调用load_dataset函数。
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()我们可以利用==matplotlib==绘制其中的图片。
plt.imshow(train_set_x_orig[27])
plt.show()得到的结果如下:

我们知道逻辑回归的输入x一般是一维向量,我们需要对 train_set_x_orig 和 test_set_x_orig 进行处理,从(209,64,64,3) 转换为(12288,209)维度,可以利用numpy库中的reshape()方法完成。numpy的shape通常返回一个元组,比如这里的 train_set_x_orig.shape 返回的元组为(209,64,64,3),所以train_set_x_orig.shape[0] 的值为 209 。
# 每一张图片是64*64*3(这里的64*64表示像素点个数,3表示每个像素点由RGB三原色构成),将其转换成列向量
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T # 得到训练集输入数据,维度为(64*64*3,209)
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T # 得到测试集输入数据,维度为(64*64*3,50)RGB的取值为0至255,我们需要将数据进行居中和标准化,将数据的每一行除以255。
# RGB的取值为(0,255),需要将数据进行居中和标准化,将数据集的每一行除以255(一般是将每一行数据除以该行数据的平均值)
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255至此,数据预处理基本完成,将上述操作封装成函数 data_preprocess 。
def data_preprocess():
"""
数据预处理
:return:
train_set_x -训练集(12288,209)
train_set_y -训练集标签(1,209)
test_set_x -测试集(12288,50)
test_set_y -测试集标签(1,50)
"""
# 获得训练集209条数据和测试集50条数据
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
plt.imshow(train_set_x_orig[27])
plt.show()
# 每一张图片是64*64*3(这里的64*64表示像素点个数,3表示每个像素点由RGB三原色构成),将其转换成列向量
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T # 得到训练集输入数据,维度为(64*64*3,209)
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T # 得到测试集输入数据,维度为(64*64*3,50)
# RGB的取值为(0,255),需要将数据进行居中和标准化,将数据集的每一行除以255(一般是将每一行数据除以该行数据的平均值)
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
return train_set_x, train_set_y, test_set_x, test_set_y2.模型的封装

我将逻辑回归封装成类 SimpleLogistic ,主要包括一下几个部分:初始化,sigmoid函数,前向传播和反向传播计算梯度,参数优化,结果预测和主控模型。
初始化:输入向量维度,迭代次数,学习率,权重矩阵和偏移量。
def __init__(self, dim, learning_rate, num_iterations):
"""
初始化逻辑回归模型
:param dim: 输入向量的维度
:param learning_rate: 梯度下降的学习率
:param num_iterations: 梯度下降迭代次数
"""
self.dim = dim
self.learning_rate = learning_rate
self.num_iterations = num_iterations
self.w = np.zeros(shape=(self.dim, 1))
self.b = 0sigmoid 函数:
def sigmoid(self, z):
"""
:param z: 任何大小的标量或数组
:return: sigmoid(z)
"""
return 1 / (1 + np.exp(-z))计算前向传播和反向传播并计算梯度(propagate):
def propagate(self, X, Y):
"""
实现前向和后向传播的成本函数及其梯度
:param X:矩阵类型为(num_px * num_px * 3,训练数量)
:param Y:真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(1,训练数据数量)
:return:
grads -梯度计算结果
cost -损失函数的结果
"""
m = X.shape[1]
# 正向传播
A = self.sigmoid(np.dot(self.w.T, X) + self.b)
cost = (-1 / m) * np.sum(Y * np.log(A) + (1 - Y) * (np.log(1 - A)))
# 反向传播
dw = (1 / m) * np.dot(X, (A - Y).T)
db = (1 / m) * np.sum(A - Y)
assert (dw.shape == self.w.shape)
assert (isinstance(db, float) or isinstance(db, int))
cost = np.squeeze(cost)
assert (cost.shape == ())
grads = {
"dw": dw,
"db": db
}
return grads, cost优化参数(optimize):主要根据迭代次数和学习率,进行梯度下降,来对w和b的值进行更新
def optimize(self, X, Y, print_cost=False):
"""
通过梯度下降算法来优化w和b
:param X:维度为(num_px * num_px * 3,训练数据的数量)的数组。
:param Y:真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(1,训练数据的数量)
:param print_cost:每一百步打印损失值
:return:
"""
costs = []
for i in range(self.num_iterations):
grads, cost = self.propagate(X, Y)
dw = grads["dw"]
db = grads["db"]
self.w = self.w - self.learning_rate * dw
self.b = self.b - self.learning_rate * db
if i % 100 == 0:
costs.append(cost)
if print_cost and (i % 100 == 0):
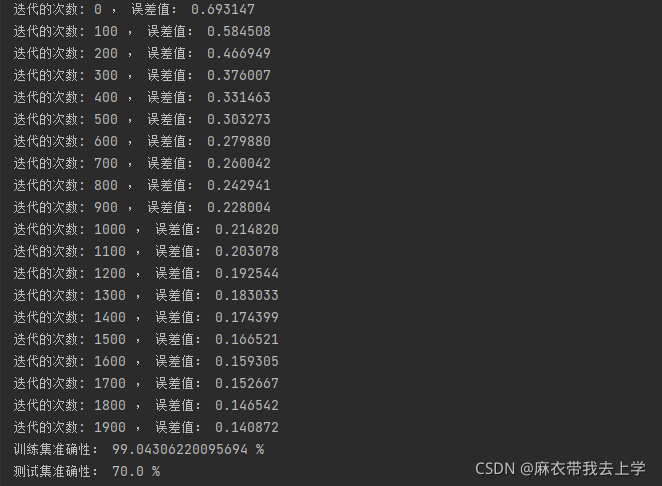
print("迭代的次数: %i , 误差值: %f" % (i, cost))
grads = {
"dw": dw,
"db": db}
return grads, costs结果预测(predict):当optimize完成后,我们可以根据优化后的参数来对图片进行分类。
def predict(self, X):
"""
使用学习逻辑回归参数logistic (w,b)预测标签是0还是1
:param X:维度为(num_px * num_px * 3,训练数据的数量)的数据
:return: Y_prediction - 包含X中所有图片的所有预测【0 | 1】的一个numpy数组(向量)
"""
m = X.shape[1]
Y_prediction = np.zeros((1, m))
w = self.w.reshape(X.shape[0], 1)
# 预测猫在图片中的概率
A = self.sigmoid(np.dot(w.T, X) + self.b)
for i in range(A.shape[1]):
Y_prediction[0, i] = 1 if A[0, i] > 0.5 else 0
assert(A.shape == (1, m))
return Y_prediction主控模型(model):需要一个主控函数来对上述操作进行控制。
def model(self, X_train, Y_train, X_test, Y_test, print_cost=True):
"""
构建逻辑回归模型
:param X_train:numpy的数组,维度为(num_px * num_px * 3,m_train)的训练集
:param Y_train:numpy的数组,维度为(1,m_train)(矢量)的训练标签集
:param X_test:
:param Y_test:
:param print_cost:
:return:
"""
assert (self.w.shape == (self.dim, 1))
assert (isinstance(self.b, float) or isinstance(self.b, int))
grads, costs = self.optimize(X_train, Y_train, print_cost) # 模型训练
Y_prediction_test = self.predict(X_test)
Y_prediction_train = self.predict(X_train)
print("训练集准确性:", format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100), "%")
print("测试集准确性:", format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100), "%")
d = {
"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediciton_train": Y_prediction_train,
"w": self.w,
"b": self.b,
"learning_rate": self.learning_rate,
"num_iterations": self.num_iterations}
return d3.模型的调用
我们通过 data_preprocess 对数据进行预处理,得到训练集和测试集,将训练集送到 SimpleLogistic 类中进行训练,训练完成后在测试集上进行测试。
if __name__ == '__main__':
train_set_x, train_set_y, test_set_x, test_set_y = data_preprocess()
dim = train_set_x.shape[0]
learning_rate = 0.005
num_iterations = 2000
logistic = SimpleLogistic(dim=dim, learning_rate=learning_rate, num_iterations=num_iterations)# 初始化模型
result = logistic.model(train_set_x, train_set_y, test_set_x, test_set_y)
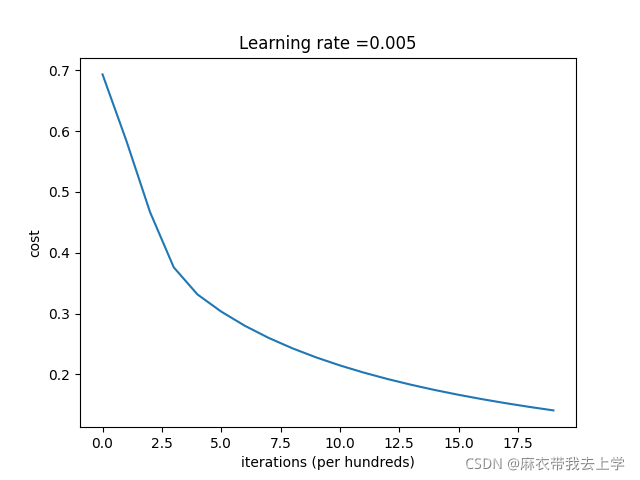
costs = np.squeeze(result['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(result["learning_rate"]))
plt.show()4.结果展示
总结
此次作业大致分为两个步骤:1.数据预处理:读取数据,将其转换成模型能处理的格式,然后将其划分成训练集和测试集。2.模型的搭建:设计sigmoid函数(根据numpy库比较好实现);根据前传播和反向传播计算梯度(propagate);根据迭代次数和学习率,利用propagate模块计算得到的梯度来对参数进行更新(optimize);根据optimize的结果,来对新样本进行预测(predict);主控函数来管理这些操作的进行,让外部仅输入维度(维度其实也可以省略),训练集,测试集,迭代次数和学习率即可得到一个训练好的逻辑回归分类器(model)。
吴恩达老师在上课时讲过,深度学习涉及到许多复杂的矩阵运算,多使用 assert 来对矩阵的维度进行监督。
此次代码已经放到百度网盘中,提取码:k4ly。代码不是很完善,请见谅。
