
声明
本博客只是记录一下本人在深度学习过程中的学习笔记和编程经验,大部分代码是参考了【中文】【吴恩达课后编程作业】Course 4 - 卷积神经网络 - 第一周作业这篇博客,对其代码实现了复现,但是原博客中代码使用的是tensorflow,而我在学习生活中主要用到的是pytorch,所以此次作业我使用pytorch框架来完成。代码或文字表述中还存在一些问题,请见谅,之前的博客也是主要参考这个大佬。下文中的完整代码已经上传到百度网盘中,提取码:iw7j。
所以开始作业前,请大家安装好pytorch的环境,我代码是在服务器上利用gpu加速运行的,但是cpu版本的pytorch也能运行,只是速度会比较慢。
一、问题描述
【中文】【吴恩达课后编程作业】Course 4 - 卷积神经网络 - 第一周作业 里面讲述了用numpy实现padding和pooling的操作,我并未将这部分代码进行复现,本文的重点在于用pytorch复现原文中的tensorflow代码。
此次作业需要处理的任务在之前的任务中出现过:完成一个多分类器,识别图像中手势代表的数字:

与之前的作业不同的是,需要在神经网络中加入卷积层和池化层,神经网络的大致结构为:
CONV2D→RELU→MAXPOOL→CONV2D→RELU→MAXPOOL→FULLCONNECTED二、模型搭建
1.封装dataloader
pytorch提供的Dataloader和Dataset包可以很好的帮助我们加载数据,划分batch:
class Digit_data(Dataset):
def __init__(self, data_path):
super(Digit_data, self).__init__()
dataset = h5py.File(data_path, "r")
if data_path == "datasets/train_signs.h5":
dataset_set_x_orig = np.array(dataset["train_set_x"][:]) # your train set features
dataset_set_y_orig = np.array(dataset["train_set_y"][:]) # your train set labels
else:
dataset_set_x_orig = np.array(dataset["test_set_x"][:]) # your train set features
dataset_set_y_orig = np.array(dataset["test_set_y"][:]) # your train set labels
dataset_set_x_orig = dataset_set_x_orig.astype("float32") / 255
dataset_set_y_orig = dataset_set_y_orig.astype("float32")
self.x_data = torch.from_numpy(dataset_set_x_orig)
self.y_data = torch.from_numpy(dataset_set_y_orig)
self.len = self.y_data.size()[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len因为训练集数据文件和测试集数据文件的数据结构不太一致,需要通过文件路径判断是训练集还是测试集,然后抽取数据集和标签集。
2.模型封装
import torch
class CNN_digit(torch.nn.Module):
def __init__(self):
super(CNN_digit, self).__init__()
self.conv2d1 = torch.nn.Conv2d(in_channels=3, out_channels=8, stride=1, padding=1, kernel_size=4)
self.relu1 = torch.nn.ReLU()
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=8, stride=8, padding=1)
self.conv2d2 = torch.nn.Conv2d(in_channels=8, out_channels=16, stride=1, padding=0, kernel_size=2)
self.relu2 = torch.nn.ReLU()
self.maxpool2 = torch.nn.MaxPool2d(kernel_size=4, stride=4)
self.fc = torch.nn.Linear(16, 6)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
conv2d1 = self.conv2d1(x)
relu1 = self.relu1(conv2d1)
maxpool1 = self.maxpool1(relu1)
conv2d2 = self.conv2d2(maxpool1)
relu2 = self.relu2(conv2d2)
maxpool2 = self.maxpool2(relu2)
batch_size = maxpool2.size()[0]
maxpool2 = maxpool2.view(batch_size, -1)
fc = self.fc(maxpool2)
return fc
def test(self, x):
y_pred = self.forward(x)
y_predict = self.softmax(y_pred)
return y_predict 将整个神经网络结构封装成类 ==CNN_digit== ,包含两个卷积层和一个全连接层,卷积层的操作包括:卷积,非线性激活和最大池化。
前向传播函数 ==forward== 中,依次计算各层的输出,需要注意的是第二层卷积层的输出送到全连接层之前需要进行维度变化,将单个样本转换成一维向量。另外,前向传播时不需要经过softmax层,因为损失函数包含softmax的功能。
==test== 函数的作用是进行预测,因此再调用forward后,需要再经过softmax层的处理。
3.主控函数
训练一个神经网络模型我个人习惯喜欢划分为以下步骤:
1.定义需要的参数:epoch,学习率。minibatch_size等。
2.用Dataloader加载训练数据。
3.初始化模型,初始化损失函数,定义优化器。
4.开始训练。定义需要的参数,用Dataloader加载训练数据:
# 定义一些需要使用到的参数
num_epoch = 200
learning_rate = 0.00095
minibatch_size = 32
costs = []
# 加载训练数据
train_data = Digit_data(train_data_path)
train_data_loader = DataLoader(train_data, shuffle=True, batch_size=minibatch_size)初始化模型,定义损失函数,定义优化器:
# 初始化模型,初始化损失函数,定义优化器
m = CNN_digit()
m.to(device) # 使用GPU加速
loss_fn = torch.nn.CrossEntropyLoss() # 使用交叉熵损失
optimizer = torch.optim.Adam(m.parameters(), lr=learning_rate) # 使用Adam优化算法开始训练:
for epoch in range(num_epoch):
cost = 0
for i, data in enumerate(train_data_loader):
img_data, img_label = data
img_data = img_data.permute(0, 3, 1, 2) # 将维度从(32,64,64,3)转换为(32,3,64,64)
img_data = img_data.to(device)
img_label = img_label.to(device)
optimizer.zero_grad()
y_pred = m.forward(img_data)
loss = loss_fn(y_pred, img_label.long())
loss.backward()
optimizer.step()
cost = cost + loss.cpu().detach().numpy()
costs.append(cost / (i + 1))
if epoch % 5 == 0:
print("epoch=" + str(epoch) + ": " + "loss=" + str(cost / (i + 1)))在测试集和验证集上计算准确率:
# 计算准确率
test_data = Digit_data(test_data_path)
test_data_loader = DataLoader(test_data, shuffle=True, batch_size=minibatch_size)
acc_train = 0
acc_test = 0
correct_train = torch.zeros(1).squeeze().cuda()
total_train = torch.zeros(1).squeeze().cuda()
for i, data in enumerate(train_data_loader):
img_data, img_label = data
img_data = img_data.permute(0, 3, 1, 2)
img_data = img_data.to(device)
img_label = img_label.to(device)
pred = m.test(img_data)
prediciton = torch.argmax(pred, dim=1)
correct_train += (prediciton == img_label).sum().float()
total_train += len(img_label)
acc_train = (correct_train / total_train).cpu().detach().data.numpy()
print("训练集上准确率为:"+str(acc_train))
correct_test = torch.zeros(1).squeeze().cuda()
total_test = torch.zeros(1).squeeze().cuda()
for j, data in enumerate(test_data_loader):
img_data, img_label = data
img_data = img_data.permute(0, 3, 1, 2)
img_data = img_data.to(device)
img_label = img_label.to(device)
pred = m.test(img_data)
prediciton = torch.argmax(pred, dim=1)
correct_test += (prediciton == img_label).sum().float()
total_test += len(img_label)
acc_test = (correct_test / total_test).cpu().detach().data.numpy()
print("测试集上准确率为:" + str(acc_test))三、模型测试结果
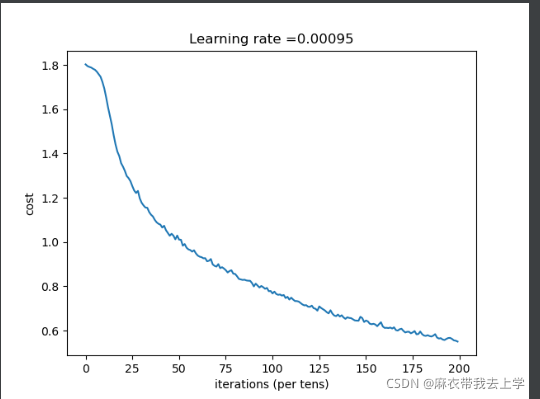

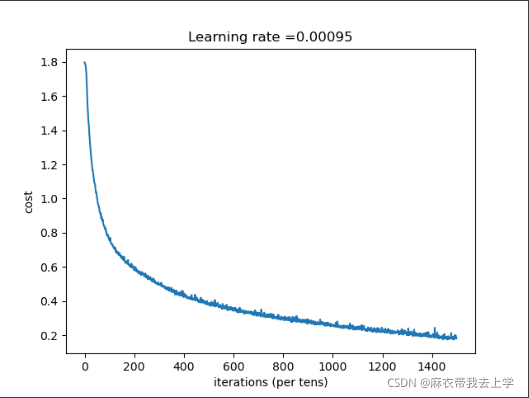
增加epoch至1500:

我们知道padding的模式有两种 ==valid== 和 ==same== ,但是pytorch不支持模式的选择(tensorflow支持),所以在代码中只是将padding的层数设置为1,没用使用 ==same== 的填充方式。
