
前言
本系列主要是对pytorch基础知识学习的一个记录,尽量保持博客的更新进度和自己的学习进度。本人也处于学习阶段,博客中涉及到的知识可能存在某些问题,希望大家批评指正。另外,本博客中的有些内容基于吴恩达老师深度学习课程,我会尽量说明一下,但不敢保证全面。
一、前置知识
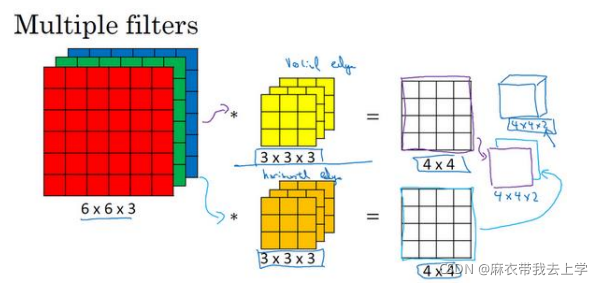
上图就是一个多过滤器(过滤器也被称作为卷积核)卷积层的操作,输入为(6,6,3)的矩阵,输出为(4,4,2)的矩阵。
对于输入(6,6,3)矩阵,我们称前两位(6,6)为"宽"和"高",最后一位"3"为通道数(channels)。
卷积核的宽和高(一般称为kernel_size,卷积核的形状一般为正方形,即宽和高相同)可以和输入不同,但是通道数必须与输入相同。从图中可以看出卷积核可以有降维的作用。卷积核可以允许有多个,最后卷积层输出值的维度与卷积核的个数相同。
二、torch.nn.Conv2d
pytorch官方文档对于Conv2d的解释为:
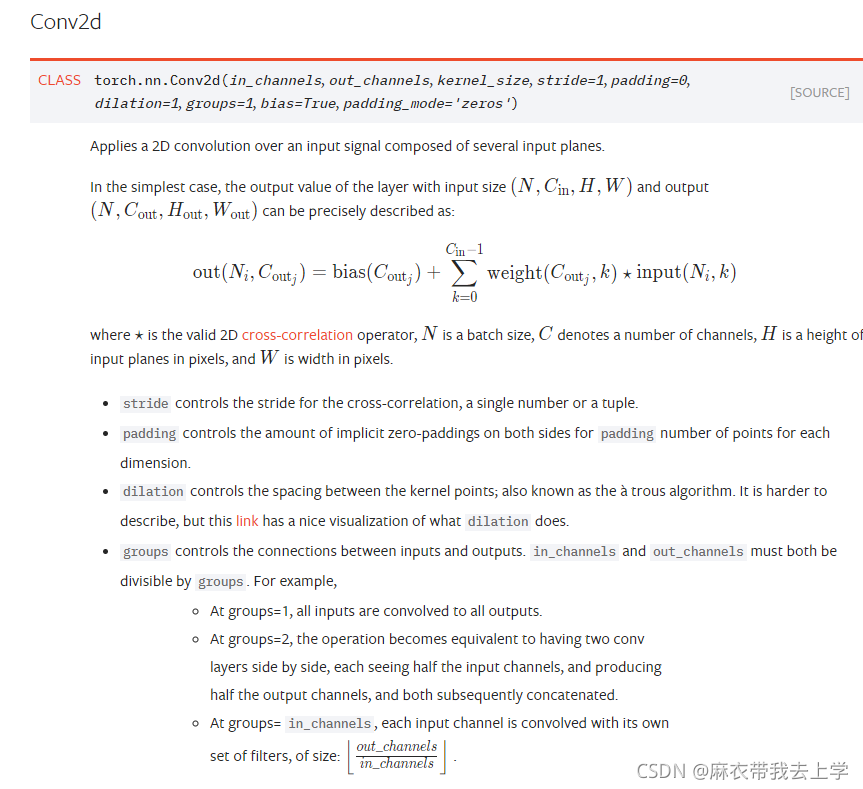
可以看出Conv2d初始化参数挺多的,其中 ==stride== 表示步长;==padding== 设置填充的值,一般为0;==bias== 表示是否添加偏移向量;== padding_mode== 表示填充的类型,这些参数也比较重要,但是我们重点要讨论的参数是 ==in_channels== ,==out_channels==,==kernel_size== 。
==in_channels== 代表的是输入通道数,如果是一张彩色图像的话,通道数一般为3,代表RGB。==out_channels== 代表的是输出通道数,==kernel_size== 代表的是卷积核的大小。
1.初始化Conv2d需要传入输入的通道数,但是不需要传入输入的"宽"和"高"
2.out_channels 代表的是输出通道数,也就是卷积核的数量
3.kernel_size表示卷积核的大小,即卷积核的"宽"和"高",如果传入的是一个数则表示卷积核的高和宽相同,可以传入一个元组来设置卷积核的长和宽不同。 通过设置 ==in_channels== ,==out_channels== 和 ==kernel_size== 就可以初始化一个简单的卷积层。需要注意的是,卷积层并不关心你输入样本的高和宽,==out_channels== 是输出通道数也就是卷积核的数量。

初始化卷积层后,我们需要将样本数据送入计算,根据pytorch的官方文档,输入要求的维度为(样本数,通道数,高度,宽度)。但是我们通常读取图片并进行批处理后的维度为(样本数,高,宽,通道数),需要再进行维度的转换,==permute()== 就可以完成这个操作。
三、torch.nn.Conv1d
Conv2d通常是处理图像这种高维输入,Conv1d处理文本这种低维输入。pytorch官方文档对Conv1d的解释如下:

单从参数上来看其实和Conv2d差别不大,这里不再做过多的解释。图像中的宽,高和通道数其实挺好理解的,但是应用到文本问题中其实并不是特别直观,这部分我主要参考了pytorch之nn.Conv1d详解 这篇博客,一般而言我们将词向量的长度作为通道数。

conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2)
input = torch.randn(32,35,256)
# batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len
input = input.permute(0,2,1)
out = conv1(input) 这里给出了一个简单的例子,我们随机初始化了一个维度为(32,35,256)的tensor矩阵,32表示batch_size,35表示句子最大长度,256表示词向量长度。我们将其送到卷积层之前需要进行维度转换,根据pytorch的官方文档,输入的维度应该为(样本数,通道数,句子长度),所以要将矩阵从(32,35,256)转换为(32,256,32)。
这里输出通道设置为100,表明有100个卷积核。卷积核的大小为2,卷积核的通道数要和输入的通道数一致,所以单个卷积核的维度为(256,2)。单个样本计算过程如下:

所以单个样本经过卷积操作后,维度变为(1,34),一共有100个卷积核则单个样本的输出为(100,34),批处理操作时一次处理32个样本,所以最终的输出维度为(32,100,34)。