
前言
本文只涉及到scrapy爬虫项目的基础知识,不涉及网页信息的提取和反爬机制的处理等具体技术,由于本人对爬虫的学习比较浅显,有出错的地方欢迎指正.
一、什么是爬虫?
我相信能点进这份博客的人可能已经对爬虫有了大致了解,简单来说爬虫就是为了信息的获取,这些信息通常也能通过人工的方式获取,但是数据量一旦庞大起来,通过人工的方式就显得十分的不切实际,而爬虫程序可以为我们处理这些简单的重复无意义的操作.
通常而言,我们不会直接说我们在"爬数据",会比较高大上的说我们在做"数据规整"的工作.
关于爬虫的具体原理本人也不是特别清楚,我的理解是,通过爬虫程序向指定网站发送请求信息request,网站会给你一个回复报文response,熟悉web的同学应该知到,这个response中就包含了我们需要的信息,通常来说,这个response会被浏览器进行编译和执行,转换成我们熟悉的前端界面,我们需要的信息就包含在这个前端界面中,因此我们需要的信息也存在于这个response中.
简单来说,爬虫的工作是"伪装"成浏览器访问某一站点,再"伪装"成用户在这个站点中查询相关信息,最后拦截得到站点返回给浏览器的response,从中筛选得到我们需要的信息.
<hr style=" border:solid; width:100px; height:1px;" color=#000000 size=1">
可能这一部分的讲解有点不太清楚,感兴趣的同学可以查阅其他资料
二、什么是scrapy
scrapy是python自带的一个爬虫框架,scrapy已经帮我们完成了许多工作,而我们只需要定制开发几个模块即可,这就使得开发一个爬虫程序变得十分简单.
三、新建一个scrapy项目
在新建一个项目之前,需要使用anaconda新建一个虚拟环境,然后下载需要使用的包,这里需要使用的包是scrapy.
在虚拟环境建立完成后,可以通过命令行的方式新建一个scrapy项目,主要分为三个步骤:
- 进入保存项目的文件目录
- 激活虚拟环境
- scrapy startproject name 来新建scrapy项目.
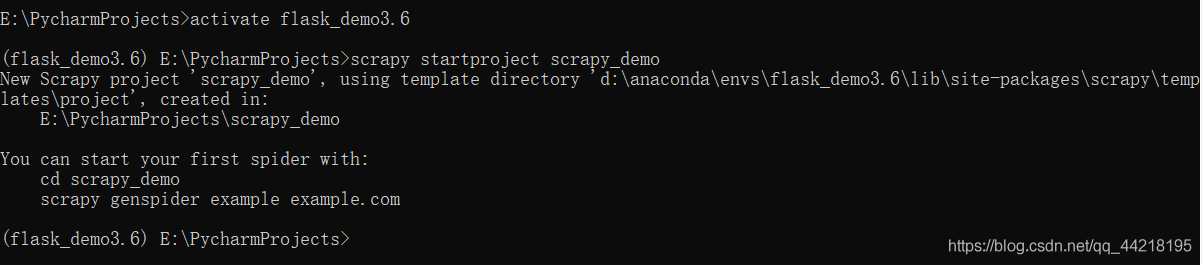
上图中我省去了步骤1.
成功创建scrapy项目后,目录如下:
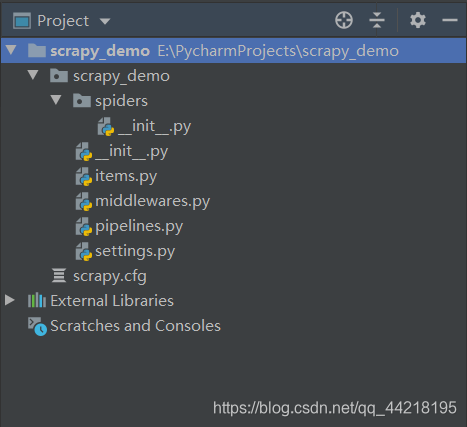
为了介绍更加方便,接下来我将以一个已经完成的完整的scrapy项目进行描述.一个完整的scrapy项目目录如下:
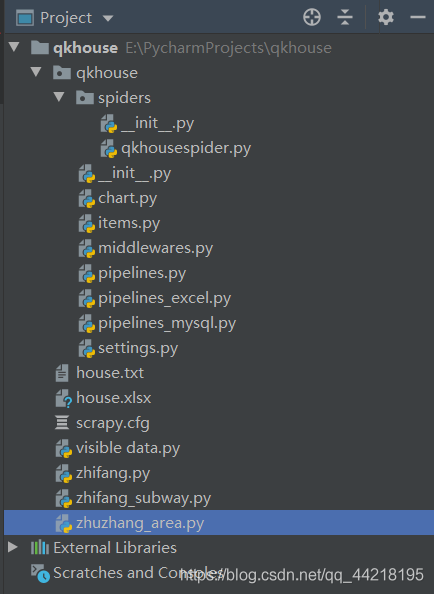
通过对比两张图可以看出,一个完整的scrapy项目只是多了几个py文件,大体结构并未改变.
四、各模块的作用
4.1 item.py
将需要爬取的信息封装成一个类,方便后期数据的保存,我的爬虫代码中需要保存房屋的价格,位置,楼层,社区,朝向,周围地铁等信息.
代码示例如下:
import scrapy
class QkhouseItem(scrapy.Item):
price = scrapy.Field()
location = scrapy.Field()
floor = scrapy.Field()
community = scrapy.Field()
orientation = scrapy.Field()
subway = scrapy.Field()
pass4.2 pipelines.py
pipelines.py是随着项目的创建而自动创建的,该模块主要是完成数据保存到外部文件中.在完整的代码中,一共有三个pipelines模块:pipelines.py将数据保存到txt文件中,pipelines_excel.py将数据保存到excel表格中,pipelines_mysql.py将数据保存到mysql数据库中.
pipelines.py代码如下:
class QkhousePipeline:
def process_item(self, item, spider):
global index
with open("house.txt", "a", encoding='utf8') as fp:
fp.write(item['price'] + "\t")
fp.write(item['location'] + "\t")
fp.write(item['floor'] + "\t")
fp.write(item['community'] + "\t")
fp.write(item['orientation'] + "\t")
fp.write(item['subway']+ "\t")
fp.write("\n")
fp.close()
return itempipelines_excel.py代码如下:
from openpyxl import Workbook
index = 2
wb = Workbook()
sheet = wb.create_sheet("租房信息")
sheet.cell(row=1, column=1, value="位置")
sheet.cell(row=1, column=2, value="小区")
sheet.cell(row=1, column=3, value="价格")
sheet.cell(row=1, column=4, value="楼层")
sheet.cell(row=1, column=5, value="地铁")
sheet.cell(row=1, column=6, value="朝向")
class QkhousePipeline:
def process_item(self, item, spider):
global index
"""保存到excel中"""
sheet.cell(row=index, column=1, value=item['location'])
sheet.cell(row=index, column=2, value=item['community'])
sheet.cell(row=index, column=3, value=item['price'])
sheet.cell(row=index, column=4, value=item['floor'])
sheet.cell(row=index, column=5, value=item['subway'])
sheet.cell(row=index, column=6, value=item['orientation'])
wb.save("house.xlsx")
index += 1
return itempipelines_mysql.py代码如下:
import pymysql
pc = pymysql.connect(host='', user="", password="",
database="test", port=3306,
charset='UTF8MB4')
cs = pc.cursor()
sql = "show tables"
cs.execute(sql)
# print(cs.fetchall())
for i in cs.fetchall():
if i[0] == 'qkhouse':
print('表已经存在')
break
else:
sql = '''
create table qkhouse(
sno int primary key auto_increment,
location varchar(100),
community varchar(100),
floor varchar(20),
Orientation varchar(10),
price varchar(200),
subway varchar(100)
)character set 'UTF8MB4'
'''
cs.execute(sql)
class QkhousePipeline:
def process_item(self, item, spider):
global pc, cs
"""保存到数据库中"""
try:
pc.ping(reconnect=True)
with pc.cursor() as cs2:
sql = "insert into qkhouse (location, community, floor, Orientation, price, subway) values (%s, " \
"%s, %s, %s, %s, %s) "
cs2.execute(sql, [item['location'], item['community'], item['floor'], item['orientation'],
item['price'], item['subway']])
pc.commit()
except Exception as e:
print(e)
pc.rollback()
finally:
pc.close()
return item你也可以将这些保存方式写在一个pipelines.py文件中,但是不方便代码的管理.
分成多个pipelines时,你需要修改setting.py中的代码,在65行附件有一段注释掉的代码:
#ITEM_PIPELINES = {
# 'qkhouse.pipelines.QkhousePipeline': 300,
#}若你只有一个pipelines,直接取消注释即可,代码中的300表示优先级,因为只有一个pipelines,所以优先级设置的大小没有影响.
若有多个pipelines时,你就需要设置pipelines优先级的大小:
ITEM_PIPELINES = {
'qkhouse.pipelines.QkhousePipeline': 1,
'qkhouse.pipelines_excel.QkhousePipeline': 2,
'qkhouse.pipelines_mysql.QkhousePipeline': 3,
}4.3 qkhousespider.py
在刚创建的scrapy项目的spider目录下,只有一个init文件,我们需要在该目录下创建一个新的模块完成核心程序的编写.
import scrapy
from bs4 import BeautifulSoup
from ..items import QkhouseItem
class QkhouseSpider(scrapy.Spider):
name = 'qkhousespider'
allowed_domains = ['wh.qk365.com']
start_urls = ['https://wh.qk365.com/list/p1']
def parse(self, response):
house_data = BeautifulSoup(response.body.decode('utf8'), 'html.parser')
elem = house_data.find_all("div", {"class": "w1170 clearfix"})[0].ul.children
index = 1
for i in elem:
if index % 2 == 1:
index += 1
else:
url = i.a['href']
index += 1
yield scrapy.Request(url=url, callback=self.parse_detail)
next = house_data.find_all("p", {"class": "easyPage"})[0]
next_url = next.contents[len(next.contents)-2]['href']
if next.contents[len(next.contents)-2]['onclick'] != "next.contents[len(next.contents)-2]['onclick']":
yield scrapy.Request(url=next_url, callback=self.parse)
print(next_url)
pass
def parse_detail(self, response):
item = QkhouseItem()
house_detail = \
BeautifulSoup(response.body.decode('utf8'), 'html.parser').find_all("dl", {"class": "houSurvey clearfix"})[
0].contents
house_detail_lf = house_detail[1]
house_detail_rg = house_detail[3]
item['price'] = house_detail_lf.contents[1].text[5:12]
item["orientation"] = house_detail_lf.contents[5].text[6:8]
item['floor'] = house_detail_lf.contents[7].text[5:]
item['community'] = house_detail_lf.contents[9].text[5:]
item['subway'] = house_detail_rg.contents[3].text.replace(u'\xa0\r\n\t\t\t\t', u',').replace(u'\n', u',')[6:]
item['location'] = house_detail_rg.contents[7].text.replace(u'\xa0\r\n\t\t\t\t', u',')[6:]
yield item因为涉及到爬取二级网页所以有parse和parse_detail两个函数,关于信息的提取我使用的是BeautifulSoup,关于数如何提取,建议看看其他大佬的博客,如果以后还有机会用到scrapy我也会补全这份内容(这部分知识丢的太久了,忘记了).
在parse_detail函数中,返回值用的是yield,这是python中的特有语法,你可以看成是每一次保存的item对象都"传输"到pipelines中进行保存.
4.4 settings.py
在配置文件中,我们之前提到过的pipelines需要对其进行修改外,还需要做其他的变动.
20行的代码改为:
ROBOTSTXT_OBEY = False另外,很多网站具备反爬机制,也需要修改相应的配置文件.
4.5 其他文件
middlewares.py是项目自动生成的,目前我没有遇到过修改该文件的情形.
最后四个py文件,是算法可视化的模块,利用matplotlib来绘制表格图形,这是建立在将爬取的数据保存为外部文件的基础上进行的,算法可视化也不是必须的操作.
五、启动scrapy
scrapy的启动需要在终端输入命令:scrapy crawl name
scrapy crawl qkhousespider我的程序中,在spider目录下面的qkhousespider.py文件中,可以看到==name==设置的值为qkhousespider.