
前言
本博客只是记录一下本人在深度学习过程中的学习笔记和编程经验,大部分代码是参考了【中文】【吴恩达课后编程作业】Course 4 - 卷积神经网络 - 第二周作业这篇博客,对其代码实现了复现,但是原博客中代码使用的是tensorflow,而我在学习中主要用到的是pytorch,所以此次作业我使用pytorch框架来完成。代码或文字表述中还存在一些问题,请见谅,之前的博客也是主要参考这个大佬。下文中的完整代码已经上传到百度网盘中,提取码:0qse。
所以开始作业前,请大家安装好pytorch的环境,我代码是在服务器上利用gpu加速运行的,但是cpu版本的pytorch也能运行,只是速度会比较慢。
一、问题描述
此次作业的主要目的是使用残差网络实现深层卷积神经网络完成分类问题,这次作业提供了两个分类问题的数据集,一个是二分类,一个是多分类,其实分类问题的解决思路都大同小异,这篇博客主要通过讲述多分类问题来对代码进行讲解。
多分类问题也还是之前的识别手势代表的数字,这里就不再过多的描述。

原博客中使用50层的残差网络,本博客使用的是34层的残差网络,pytorch代码主要参考博客:从头学pytorch(二十):残差网络resnet 。
二、前置知识和模型架构
1.残差网络的基本知识
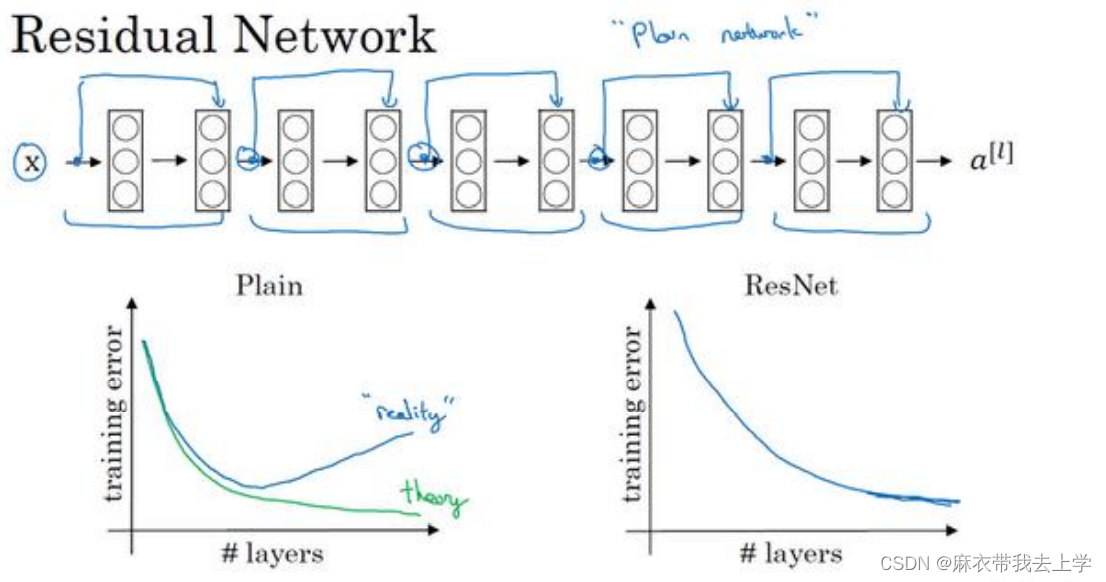
残差网络的基本原理和计算规则其实挺容易理解的,我们以一个残差块为基本单位进行研究:
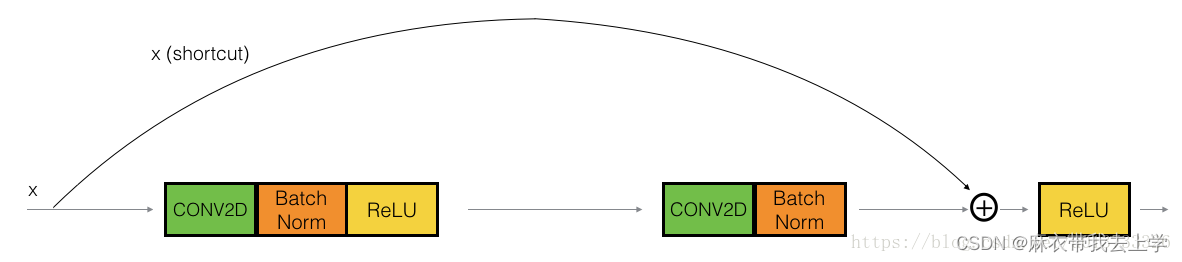
对于一个残差块而言,它与基本的神经网络的区别在于,残差块最后通过非线性函数激活输出的时候需要加上残差块最开始的输入,明白这一点后用编程实现起来其实并不复杂。
2.模型架构
模型架构问题我并没有深究,这里主要通过论文中的两张图来进行简单的说明一下:

上图来自原论文:Deep Residual Learning for Image Recognition 中截取下来,图中绘制了三种神经网络的基本结构:VGG-19,传统的卷积网络(Plain)和残差网络(ResNets),从结构来看,残差网络只是在传统的卷积网络中添加了跳跃连接(skip connection),我们可以以残差块为基本单元构造神经网络。
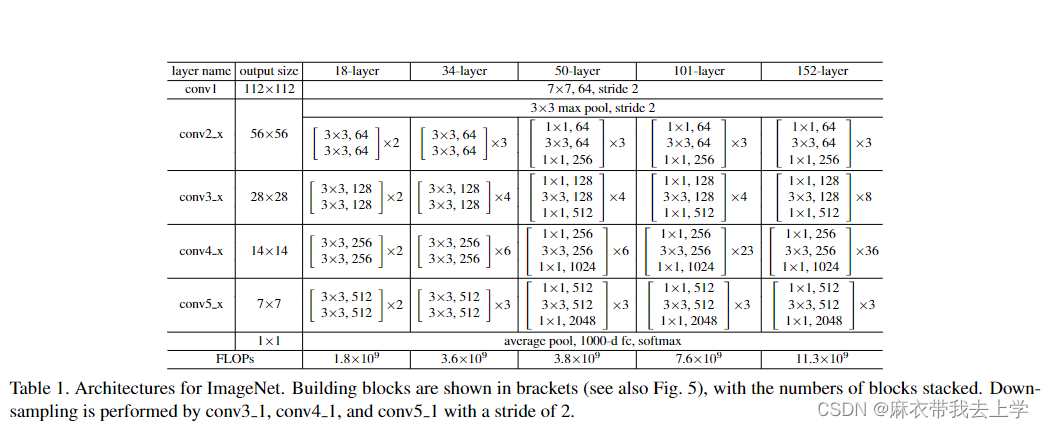
论文中还给出了不同层数的残差网络对应的一个具体结构,这也是我编写代码的一个基本标准。以34层的残差网络为例,主要分为五个部分(最后还有全连接层等操作):
1.conv1:基本的卷积层,无残差操作,卷积核大小为7, 卷积核个数为64,步长为2
2.conv2_x:一个最大池化层和三个残差块,要求最后输出的通道数为64
3.conv3_x:四个残差块,最后输出的通道数为128
4.conv4_x:六个残差块,最后输出的通道数为256
5.conv5_x:三个残差块,最后输出的通道数为512
三、编程实现
1.Dataloader加载数据
import h5py
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
class Image_Data(Dataset):
def __init__(self, data_path):
super(Image_Data, self).__init__()
# 读取数据集
dataset = h5py.File(data_path, "r")
if data_path == "datasets/train_happy.h5" or data_path == "datasets/train_signs.h5":
data_set_x_orig = np.array(dataset["train_set_x"][:])
data_set_y_orig = np.array(dataset["train_set_y"][:])
else:
data_set_x_orig = np.array(dataset["test_set_x"][:])
data_set_y_orig = np.array(dataset["test_set_y"][:])
data_set_x_orig = data_set_x_orig.astype("float32") / 255
data_set_y_orig = data_set_y_orig.astype("float32")
self.x_data = torch.from_numpy(data_set_x_orig)
self.y_data = torch.from_numpy(data_set_y_orig)
self.len = self.y_data.size()[0]
def __getitem__(self, item):
return self.x_data[item], self.y_data[item]
def __len__(self):
return self.len
def get_shape(self):
return self.x_data.size(), self.y_data.size()
我这里使用通过继承Dataset类对数据进行了简单的封装操作,每个人的编程习惯不同,可以做相应的调整。
2.残差块的封装
class Residual(torch.nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(Residual, self).__init__()
self.stride = stride
# 卷积层使用same填充,由于pytorch没有提供自动填充的操作,需要手算填充的大小
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = torch.nn.BatchNorm2d(out_channels)
self.relu1 = torch.nn.ReLU(inplace=True)
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = torch.nn.BatchNorm2d(out_channels)
# 输入和输出通道数不同时,需要通过1x1卷积改变输入数据的通道数
if in_channels != out_channels:
self.conv1x1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv1x1 = None
def forward(self, x):
out1 = self.relu1(self.bn1(self.conv1(x)))
out2 = self.bn2(self.conv2(out1))
if self.conv1x1:
x = self.conv1x1(x)
out = self.relu1(out2 + x)
return out
残差块的大致结构为:
1.卷积conv1
2.Batch Normalization层
3.Relu
4.卷积conv2
5.Batch Normalization层
6.Relu(代码中复用了Relu,所以只定义了一个)
残差块初始化时我们需要传入输入通道数,输出通道数和步长,输入通道数为你输入数据的通道数,输出通道数为想要输出的通道数,输出通道数的设置按照论文中给出的标准来实现。
需要注意的是残差块的输入和输出的通道数可能不同,但是残差块内部的计算一般是不会改变数据的维度,所以第二个卷积函数初始化时输入和输出的通道数都为 out_channels 。
在经过最后的Relu时,我们需要将当前的计算结果加上最开始的输入,这就要保证这两个值的维度相同,所以当输入和输出的通道数不同时我们需要利用1x1卷积改变输入数据的通道数:
if in_channels != out_channels:
self.conv1x1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv1x1 = None
3.残差网络ResNets
class ResNet(torch.nn.Module):
def __init__(self, in_channels, num_classes):
super(ResNet, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(inplace=True)
)
self.conv2 = torch.nn.Sequential(
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
Residual(64, 64),
Residual(64, 64),
Residual(64, 64)
)
self.conv3 = torch.nn.Sequential(
Residual(64, 128, stride=2),
Residual(128, 128),
Residual(128, 128),
Residual(128, 128),
Residual(128, 128)
)
self.conv4 = torch.nn.Sequential(
Residual(128, 256, stride=2),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256)
)
self.conv5 = torch.nn.Sequential(
Residual(256, 512, stride=2),
Residual(512, 512),
Residual(512, 512)
)
self.avg_pool = torch.nn.AdaptiveAvgPool2d(1)
self.fc = torch.nn.Linear(512, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avg_pool(out)
out = out.view(out.size()[0], -1)
out = self.fc(out)
return out
设计残差网络主体的五个部分严格按照论文中给出的参数来设计,关于残差网络的初始化需要告知输入数据的通道数和多分类的类别个数。在经过五部分处理后,将输出进行平均池化,池化完成后展开成一维,并输入到一个全连接层中。
4.主控函数
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
from data_utils import Image_Data
from resnet_model import ResNet
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
train_happy_data_path = "datasets/train_happy.h5"
train_signs_data_path = "datasets/train_signs.h5"
test_happy_data_path = "datasets/test_happy.h5"
test_signs_data_path = "datasets/test_signs.h5"
if __name__ == "__main__":
# 初始化训练要使用到的参数
num_epoch = 50
learning_rate = 0.01
batch_size = 32
costs = []
classes = 6
# 加载数据
train_data = Image_Data(train_signs_data_path)
train_data_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
test_data = Image_Data(test_signs_data_path)
test_data_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size)
# 初始化网络,图像的通道数为3
m = ResNet(3, num_classes=classes)
m = m.to(device)
# 定义交叉熵损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.Adam(m.parameters(), lr=learning_rate)
# 开始训练
for epoch in range(num_epoch):
cost = 0
for i, data in enumerate(train_data_loader):
img_data, img_label = data
img_data = img_data.permute(0, 3, 1, 2)
img_data = img_data.to(device)
img_label = img_label.to(device)
optimizer.zero_grad()
y_pred = m.forward(img_data)
loss = loss_fn(y_pred, img_label.long())
loss.backward()
optimizer.step()
cost = cost + loss.cpu().detach().numpy()
costs.append(cost / (i + 1))
if epoch % 5 == 0:
print("epoch=" + str(epoch) + ": " + "loss=" + str(cost / (i + 1)))
plt.plot(costs)
plt.ylabel("cost")
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
当把模型封装完成后训练模型的代码其实千篇一律,我个人的处理习惯为:初始化训练参数,加载数据集,初始化模型,定义损失函数,定义优化器,开始训练,绘制损失曲线图。
在模型内部我并未定义预测函数,训练完成后,在训练集和标签集上做预测时,需要将模型的计算结果再通过一个softmax层。
四、结果
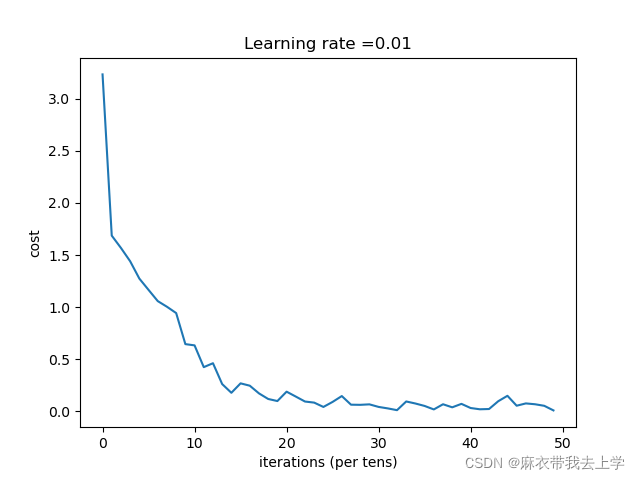

从结果来看,通过残差网络加深神经网络后,模型的表现效果变得非常好。
